
UNIX command
- stdio
- archivind and compression
##1. stdio
FILE채널에 입출력 위해 하드웨어 직접접근하지 않고 표준화된 입출력 방식을 통하도록 하는 가상화 레이어의 일종.
**file channel :file에 입출력하기 위한 통로, 파일 입출력 시 하드웨어 직접접근안코 파일채널통로 접근해 간접접근
##2. 파일채널(file channel)
#1. 파일에 입출력을 하기 위한 메타정보를 가지는 객체
1) 프로세스 스코프에서 유효. (프로세스 종료와 함께 휘발됨)
##3. 파일 서술자(file descriptor)
#1 파일기술자라 불림(줄여서 fd)
#2. 파일 채널들에게는 붙여진 유일한 식별자(identifier), 숫자로 명명
#3. 양수 0번부터 시작하여 증가
#4. 예약된 파일 서술자.
0: stdin (표준입력)
1: stdout(표준출력)
2:stderr(표준에러)
#5 프로세스 안에서만 유효, 프로세스 종료되면 휘발됨을 주의.
하기링크참조
https://dev-ahn.tistory.com/96
##4 PIPE :
#1 프로세스 간 통신 역할
=>IPC의 일종이며 Shell에서 주로 사용
#2 anonymous pipe(nameless pipe, unnamed pipe)
1. temporary (프로세스 종료시 사라짐)
1) 임시로 생성되었다가 소멸되는 파이프 = 익명 파이프
--> 셸에서 | 문자(vertical bar)를 쓰면 생성.
--> 셸의 stdio에서 배우는 것은 주로 이 익명 파이프 기능
2) 프로세스들의 직렬연결
3) 명령행에서 Vertical bar(|) 로 사용
A | B | C : A, B, C를 직렬로 연결.
A의 출력이 B의 입력과 연결, B의 출력은 C의 입력에 연결 최종 C가 종료되면서 출력.
4)사용예
//find 명령의 출력(stdout, fd값: 1)이 wc명령의 입력(stdin, fd0)과 연결[anonymous pipe]
fd1 -> fd0
$ find ~ | wc –l
==> home dir('~')를 find 한 결과가 | 매개체 통해 wc -l로 넘어가서 wc명령 입력과 연결된다**wc : word count(워드, 바이트,라인 수 등 다양한 기능 제공)
** -l 옵션 : line 수 카운팅
//anonymous pipe를 쓰지 않고 명령하려면 이와 같이 복잡하게 해야한다.
$ find ~ > tmp.txt; wc -l < tmp.txt; rm tmp.txt
5433
==> home dir을 찾아 tmp.txt에 입력하고 tmp txt라인수를 카운팅해 텍스트내용에 라인수만 입력한다
그리고 tmp.txt를 삭제한다
#3 named pipe
1. persistency (프로세스 종료되도 남아있음)
1) 유닉스에서는 named pipe의 구현체를 FIFO Pipe 라고 부른다
-->First In First Out 의 규칙으로 작동하지만 큰 의미는 없다.
2) path+filename이 있기 떄문에...
--> path를 가지는 것을 명명되었다고 표현. == 명명된 파이프
--> mkfifo 명령(or POSIX C API)를 사용하여 생성
##5 redirection(방향재지정)
#1. 채널의 방향을 다른 곳으로 연결
1) A>B : A의 stdout을 파일 B로 연결(저장) (B에 기존 파일 내용은 삭제됨)
2) A<B : A의 stdin을 파일 B로 연결
3) A>>B :방향은 >과 같고, 추가 모드
eg) sort < names.txt
eg) ls > filelist1.txt
eg) cat > a.txt //기존 a.txt 내용 삭제 후 입력 및 저장
eg) cat >> a.txt 기존 내용 뒤에 연이어 입력 및 저장
eg) strace ls 2> strace.txt
// 2는 2번파일 서술자를 파일로 연결하는 명령 (fd2, stderr의 출력을 파일로 저장하는 것)
// strace 는 ls가 실행되는걸 어떻게 내부적으로 작동하는지 추적함 아무것도 안잡으면 1번, '>' == '1>' 과 동일.
##6 cat
stdout와 파일을 자유롭게 연결해주는 기본 필터
1) 가장 자주 쓰이는 쓰임새는...
==> 파일의 내용을 stdout으로 출력하는 용도
==> stdin의 입력을 redirection해서 파일로 출력하는 용도
redirection >을 통해 mtime_b24.txt에 입력을 한 후 redirection <를 통한 출력
jlim@jlim-vm:~/temp0$ cat > mtime_b24.txt
Hello
ctrl D를 눌러서 입력 종료
jlim@jlim-vm:~/temp0$ cat < mtime_b24.txt
cat < 를 통해 출력
>> 뒤이어서 입력 , > 기존 내용 지워지고 입력
###2. 아카이브 , 압축 명령어
- tar, cpio
- gzip, xz, bzip2, zstd
#1
1. UNIX 계열에선 여러 파일 묶음 작업과 압축이 분리
1) 아카이브 유틸: tar(tape archive), cpio
=> 파일을 묶는 작업 (테이프에 보관하는 목적으로 archiving한다 불렸다)
=> tar은 UNIX의 BSD 계열, cpio 는 SysV 계열이다.
2) 압축 유틸: gzip, bzip2, xz, zstd, lz4
=> 압축, 압축해제 기능
=> 압축률 xz > bzip2, zstd > gzip > lz4 순으로 주로 사용하는 압축명령 zstd가 많이 사용됨 .
압축률 이 중요하다면 xz(속도는 느림). 속도면 zstd를 많이사용
#2 tar [ctxv] [f archive-file] files...
| c | (create)아카이브를 생성 |
| t | (test)아카이브를 테스트 |
| x | (extract) 아카이브로부터 파일을 풀어냄. |
| v | **(verbose) 상세한 정보출력 -> 실무에선 사용x |
| f archive-file | 입출력할 아카이브 파일명을 지정할 때 사용. |
| exclude file | 대상 중에 file을 제외(특정 파일을 제외할 때 사용) |
**ctxv 중 하나 넣으면 나머진 사용 x
verbose에 대하여..
** verbose 많은 인터넷 예제가 v옵션을 기본으로 사용하는데, 원래는 쓰면 안되는 옵션이다.
**verbose는 디버깅이나 확인 용도로만 사용하는 기능이다.
** tar에 v는 넣지말기. 속도 느려짐
eg. 두 명령은 동일 결과.
구버전 ‘>’ redirection 하지 않고 저장한다
$ tar c *.c > arc_c.tar //일반적인 사용방식
//redirection > 사용하지 않은 방식
//f option을 준다.
//f archive-file.
//*.c가 묶여서 파일명인 arc_c.tar에 들어감
$ tar cf arc_c.tar*.c //redirection사용x
#3
압축 프로그램 종류
| 프로그램 | 확장자 | 설명 |
| compress | Z | 거의 사용X |
| gzip | gz | GNU에서 만듦 |
| bzip2 | bz2 | 텍스트 압축에 유리(과거) |
| xz | xz | 텍스트 압축률 좋지만, 느림 |
| lz4 | lz4 | zstd보단 성능은 좋진 않지만 압축률 빠른편이며 무난한 성능 |
| zstd | zst | c언어로 개발, 멀티스레드 지원, 빠르고 중상의 압축률 |
xz , zstd 압축프로그램을 주로 사용 xz와 zstd 중엔 zstd 사용하는게 효율성측면(속도)에서 좋음
1. gzip
-d : (decompress) 압축해제
-c: 표준 출력(stdout)으로 결과물 보냄
-1, -9: (fast, better) 압축레벨 지정.
압축: tar c /etc/* .conf | gzip -c > etc.tar.gz
해제: gzip -cd etc.tar.gz | tar xtar t 라하면 t(test)로 작동

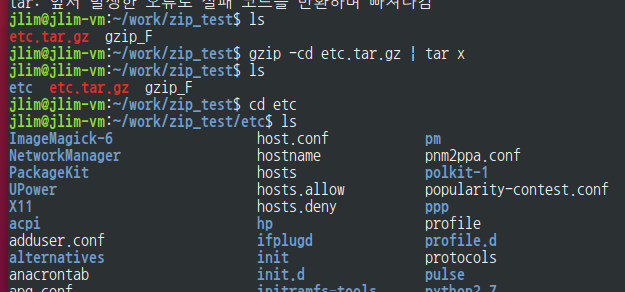
하기 블로그 통해서도 실습
아카이브 안하고 gzip만.
gzip -d 는 압축 풀기. 파일 내용 그대로 보존.
https://sidepower.tistory.com/198

**하기에서 아카이브 생성과 압축을 좀 더 실습해볼 예정
2. zstd [OPTIONS[ - |input-file] [-o output-file]
**-# : compression level [1-19] (default: 3)
**compression lv 올려도 압축율이 매우 높기에 크게 올라가지 않음
#4 아카이브 생성 및 압축을 해보자!


$ mkdir ~/tmp //현재 디렉토리에서 홈dir에 tmp 폴더 생성
$ cd !$ // !$: 방금 타이핑한 ~/tmp 를 대체 == ALT . 도 가능
$ cp-rf /etc . // etc 파일 복사
$ tar c . | gzip -c > bak_etc.tar.gz // 아카이브 생성및 압축정통파 방법으로 실제로는 자주 사용 x
#5 압축 : tar extensions
1. GNU tar 주요 옵션(리눅스 탑재된 GNU tar 만가능)
| z | 아카이브 결과물을 gzip로 압축 혹은 해제 |
| j | 아카이브 결과물을 bzip2로 압축 혹은 해제 |
| J | 아카이브 결과물을 xz로 압축 혹은 해제 |
| --zstd | 아카이브 결과물을 zstd로 압축 혹은 해제 |
| a | auto, 확장자 자동판단 |
하기는 실무에서 많이 사용하는 모던명령어 xz ,zst아카이브 생성 및 압축 명령어만 서술했습니다.
아카이브 생성 및 압축
// 고전학파 명령어
$ tar c ./data ./exp | gzip -c > back_data.tar.gz
//모던명령어
$ tar cfa back_data.tar.xz ./data ./exp // ./는 상대경로이며 하위 dir 접근 ../는 상위 dir접근
$ tar cfa back_data.tar.zst ./data ./exp //모던명령어(1.31 부터 tar zstd 지원)
멀티스레드 방식은 모던명령어 +고전학파명령어 퓨전형식으로 사용해서 아카이브 생성및 압축
$ tar c ./data ./exp | xz -T0 > back_data.tar.xz
$ tar c ./data ./exp | zstd -T0 > back_data.tar.zst //zst tar1.31이하는 pipe 사용명령어 형식 사용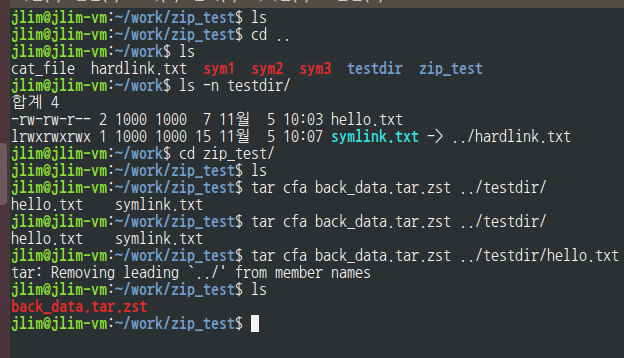
zip test 상위 dir에 있는 work dir에 하위 dir testdir에 접근하여 hello.txt 를 아카이브 생성및압축함.
상대경로및절대경로 참조 블로그
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=haejoon90&logNo=220725377063
tar:Removing leading '../' from member names 는 에러메시지가 아님.
아래는 참조 블로그
https://positivemh.tistory.com/207
압축 풀기
고전학파
$ gzip -dc back_data.tar.gz | tar x
모던명령어
$ tar xfa back_data.tar.xz
$ tar xfa back_data.tar.zst // tar zstd지원은 1.31 부터
멀티스레드(고전+모던)
$ xz -dcT0 back_data.tar.xz | tar x
$ zstd -dcT0 back_data.tar.zst | tar x // tar 1.31이하는 pipe 사용 명령어 형식 사용

a: auto
git clone https:// https://github.com/htop-dev/htop
상기 명령 그대로 붙여넣기하여 git 내용을 클론해
htop dir을 htop.tar.gz, htop.tar.xz, htop.tar.zst 로 각각 3회씩 압축하여 압축에 걸린 시간(real time)과 압축률을 계산해보자
**gz도 모던 명령 존재
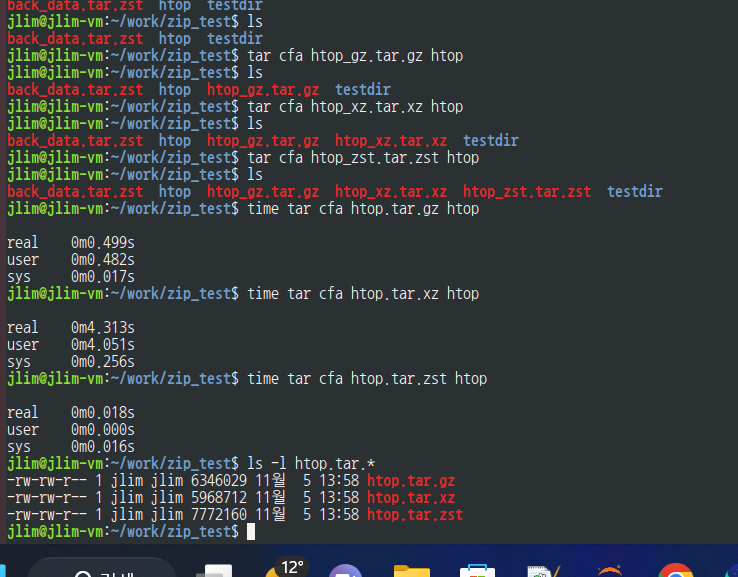
zst 형식으로 아카이브 및 압축한 것이 속도가 가장 빠르다. 그 다음엔 gz 그리고 xz 순이다.
추가로 원본 파일 삭제후 압축한 zst파일로 깃 htop폴더를 압축풀어 복구해보겠다.

해당 내용은 프로그래머스 리눅스 강의 김선영 선생님의 강의를 들으며 기록했습니다.
'프로그래머스 > 리눅스' 카테고리의 다른 글
| vim 뻑가는 경우 (0) | 2022.11.03 |
|---|---|
| 리눅스 기초(2-5) 링크에 대해 (0) | 2022.11.03 |
| 리눅스 기초 (2-3) File 관련 명령어 와 touch , find (0) | 2022.11.03 |
| 리눅스 기초 (2-2) File 관련명령어 (0) | 2022.11.03 |
| 리눅스 기초(2-1) 명령어 summary (0) | 2022.11.03 |