
REGEX syntax
- syntax: BRE, ERE
##1 POSIX REGEX: meta char
ERE (5) : ? , + , {m,n} , | , ()
BRE (7) : dot(.) , * , ^, $ , [...] , [^...] , \
https://deep-learning-challenge.tistory.com/92
[데이터베이스] Pattern match, Posix Regular Expression
[데이터베이스] Pattern match, Posix Regular Expression 데이터베이스 패턴 매치(Pattern match), Posix Regex 관련해서 공부한 내용을 포스팅하고자 합니다. 다음의 교재를 참고했음을 미리 밝힙니다. Pattern Match
deep-learning-challenge.tistory.com
Meta characters in regular expressions
\ Marks the next character as either a special character or a literal. For example, n matches the character n, whereas \n matches a newline character. The sequence \\ matches \ and \( matches (. ^ Matches the beginning of input. $ Matches the end of input.
www.ibm.com
##2 Any single character
dot/period : . - 임의의 문자
1) c.b: cab, ccb, c2b ,c^b 즉 c와 b사이에 문자 하나가 들어감
2) a..b : axyb, a^&b ...
3) a.......b : 는 quantifier, interval 기법을 적용하는게 낫다.,


**참조1
| : anonymouse pipe
앞에 있는 출력결과가 뒤에 있는 곳에 입력으로 들어감
var3이 grep에 입력으로 들어감.
**참조2
“ \$ ” $인식안시킬려면 \ (escape) 붙여서 $를 escape 시킴
“c\.b” metacharacter 인 dot 앞에 backslash 입력 시 본연 의미(meta character)를 잃고 순수하게 문자 dot이 됨
##3 Quantifier(수량자)
#1. ?, +, *, {m,n} - 수량자의 종류 는 총 4가지
=> 수량자는 선행문자 패턴(atom 이라고도 함) 을 수식하는 기능 가짐.
다음 각 패턴이 의미하는 것은?
https://learn.microsoft.com/ko-kr/dotnet/standard/base-types/quantifiers-in-regular-expressions
해당 MS 사이트 참조해서 풀어보자 !
X?ML
can*
can+
http.*
atom은 각각 X , n , n , dot(.) 이 되겠다.
1) ?: question mark
2) *: asterrisk, star
3) + plus sign
4) {} :(curly) braces
BRE : 2) * 수량자
ERE : 1) 3) 4) 수량자
#2. {m,n} - interval expression
1) abc{2,5} : abcc, abccc, abcccc
2) {n}, {n,} , {n,m} 이 표준 {,m}은 GNU extension
문제 : ?, * , +를 {} 로 표현해보아라
1) {0,} == ??
2) {,1} == ??
3) {1,} == ??
답:
1) 0~ 무한대 == *
2) 0 ~1 == ?
3) 1~무한대 == +
#3
* 는 0과 매칭이 되어 backtracking으로 느려질 가능성이 있다. 성능 중시한다면 backtracking을 피할 수 있도록 하자.
핵심은
* kleene start는 0개이상 ( 곱하기)
+ kleene plus는 1개이상이다. (더하기)
A * 0 = 0
A *1 = A
A*2 = AA
....
A +0 = A (1)
A +"1개의 A" = A
A+"2개의 A" = AA
...
#4 Quantifier (수량자) : BRE vs ERE
1) grep 은 기본값으로 BRE 작동하여, * 수량자만을 바로 사용가능
2) ERE인 수량자(*가 아닌 나머지, 상기 참조)는 \ (back slash)를 앞에 더해줘야만 grep 을 사용할 수 있다.
#5 egrep은 기본값으로 ERE 작동하여, *,+,?,{} 패턴의 모든 기능이 제공됨
##4. Anchor : 패턴 위치 지정하는 패턴
#1. 종류 : ^(caret), $ (dollar sign)
1) ^ftp : "ftp" 로 시작하는 행
2) ^$: 비어있는 행(라인) (행의 시작과 끝에 아무런 문자없음)
3) <BR>$: <BR> 로 끝나는 경우
#2. 라인[개행문자(new line)] 단위로 처리하지 않는 경우 $는 문서의 끝을 의미,.
eg. *vim :/. $s/a/b/g : a를 찾아 b로 바꿔라 // $는 마지막행
#3 Character sets
1). [ ], [^ ] - character class
1) [abcd] : a,b,c,d 중 하나
2) [0,9] : 0,1,2,..., 9
3) [a-zA-Z0-9] : 대소문자 알파벳과 숫자
4) [^0-9] : [0-9] 을 제외한 나머지 ( ^ : 여집합 기능, [ ] 안에 오는 경우에한해)
5) ^ 문자 자체를 그룹에 넣으려면 [0-9^] 만일 [^0-9] 면 (^가 [바로 뒤에오는경우는) 안됨 아니면 escape \ 사용하여 ^를 넣음.
#4 REGEX 로 단어 검색
$ grep --color "p[abcd]\+ous"
특정파일에 접근해서 단어패턴 찾아 출력해보기.
contifier : * , + , ? , {m,n} 4개
*: BRE , 나머진 ERE
grep의 matcher는 BRE matcher가 defatult 이다. ERE 사용시 앞에 \ 사용해야기에 + 앞에 \ 를 사용한거다.
#5 anchor를 이용한 패턴 수정
$ grep --color "p[abcd]\+ous$"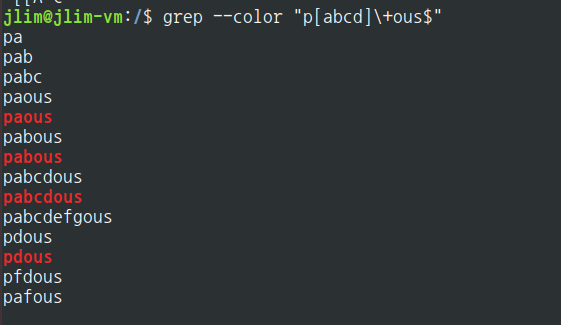
ous가 매칭의 끝부분에 등장하는 경우.
$ : $ 뒤로는 라인의 끝을 의미.
#6 log data 검색하는 경우 grep 활용해 로그를 뽑을 수 있다.
#7 grep : line control options.
| -A NUM, --after-context=NUM | print NUM lines of trailing context after matching lines |
| -B NUM, --before-context=NUM | Print NUM lines of leading context before matching lines |
| -C NUM, -NUM, --context=NUM | Print NUM lines of output context |
| --group-separator=SEP | Use SEP as a group seperator. By defaulrt SEP is double hyphen (--). |
| --no-group-separator | Use empty string as a group separator |
'프로그래머스 > 리눅스' 카테고리의 다른 글
| 리눅스 cpp 실행하기 (0) | 2022.11.27 |
|---|---|
| 참고 (0) | 2022.11.07 |
| 리눅스 기초(4-6) Bash 기초 a (0) | 2022.11.07 |
| 리눅스의 기초(4-5) ssh server (0) | 2022.11.06 |
| 리눅스의 기초 (4-4) Linux Admin - 네트워크 설정 ( 매니저) (0) | 2022.11.06 |